
So the ask is to do 3 Million Predictions per second with as little resources as possible. Thankfully its one of the simpler model of Recommendation systems, Multi Armed Bandit(MAB). Multi Armed bandit usually involves sampling from distribution like Beta Distribution. That’s where the most time is spent. If we can concurrently do as many sampling as we can, we’ll use the resources well. Maximizing Resource utilization is the key to reducing overall resources needed for the model.
Our current prediction services are micro-services written in Python, and they follow the general structure of
Request -> Features Fetch -> Predict -> Post process -> Return
A single request can require us to score thousands of user, content pairs. Python with GIL and multiprocessing can only get you so far, We have implemented batch sampling methods based on cython and C++ that get around the GIL and we use many workers based on number of cores to handle requests concurrently.
The current Python service with single node can do 192 RPS, about 400 pairs each. Only about 20% average CPU utilization. The limiting factor now was the language, the serving framework and the network call to feature store.
Why Golang?
Golang is a statically typed language with great tooling. This means that errors are caught early and it is easy to refactor code. Concurrency is native to Golang, which is important for machine learning algorithms that can be run in parallel and for concurrent network calls to featurestore. It also benchmarks as one of the fastest serving languages here. It is also a compiled language, so its optimized well at compile time.
Porting the existing MAB to Golang
Basic idea, dividing the system in 3 parts
- Basic REST API for predict and health with stubs.
- Featurestore fetch, implement a module for it.
- Lift and shift the c++ sampling code using cgo
#1 was easy, I chose Fiber framework for REST API. It seemed most welcoming, good documentation, expressjs like API. And it was also fairly up in the benchmarks.
Early code
func main() {
// setup fiber
app := fiber.New()
// catch all exception
app.Use(recover.New())
// load model struct
ctx := context.Background()
md, err := model.NewModel(ctx)
if err != nil {
fmt.Println(err)
}
defer md.Close()
// health API
app.Get("/health", func(c *fiber.Ctx) error {
if err != nil {
return fiber.NewError(
fiber.StatusServiceUnavailable,
fmt.Sprintf("Model couldn't load: %v", err))
}
return c.JSON(&fiber.Map{
"status": "ok",
})
})
// predict API
app.Post("/predict", func(c *fiber.Ctx) error {
var request map[string]interface{}
err := json.Unmarshal(c.Body(), &request)
if err != nil {
return err
}
return c.JSON(md.Predict(request))
})
That’s it, Task #1 done. Took less than an hour.
On #2, it required slightly more learning on how to make structs with methods and goroutines. One of the major differentiator from C++, Python is that Golang doesn’t support full object oriented programming, mainly it doesn’t support inheritance. It’s also completely different in how the methods on structs are defined from other languages I’ve encountered.
The Featurestore we were using had the Golang client, all I had to do was write a wrapper around it to read concurrently large number of entities.
The basic structure I was going for was
type VertexFeatureStoreClient struct {
//client reference to gcp's client
}
func NewVertexFeatureStoreClient(ctx context.Context,) (*VertexFeatureStoreClient, error) {
// client creation code
}
func (vfs *VertexFeatureStoreClient) GetFeaturesByIdsChunk(ctx context.Context, featurestore, entityName string, entityIds []string, featureList []string) (map[string]map[string]interface{}, error) {
// fetch code for 100 items
}
func (vfs *VertexFeatureStoreClient) GetFeaturesByIds(ctx context.Context, featurestore, entityName string, entityIds []string, featureList []string) (map[string]map[string]interface{}, error) {
const chunkSize = 100 // limit from GCP
// code to run each fetch concurrently
featureChannel := make(chan map[string]map[string]interface{})
errorChannel := make(chan error)
var count = 0
for i := 0; i < len(entityIds); i += chunkSize {
end := i + chunkSize
if end > len(entityIds) {
end = len(entityIds)
}
go func(ents []string) {
features, err := vfs.GetFeaturesByIdsChunk(ctx, featurestore, entityName, ents, featureList)
if err != nil {
errorChannel <- err
return
}
featureChannel <- features
}(entityIds[i:end])
count++
}
results := make(map[string]map[string]interface{}, len(entityIds))
for {
select {
case err := <-errorChannel:
return nil, err
case res := <-featureChannel:
for k, v := range res {
results[k] = v
}
}
count--
if count < 1 {
break
}
}
return results, nil
}
func (vfs *VertexFeatureStoreClient) Close() error {
//close code
}
Tips on Goroutine
Always try to use channels, there are many tutorials using sync workgroups for Goroutine. Those are lower level APIs you won’t need for most cases. Channels are elegant way to run goroutines even if you don’t need to pass data, you can send flags in channel to collect. Goroutines are cheap virtual threads, you don’t have to worry about making too many of them and running on multiple cores. The latest golang can run that across cores for you.
On #3, it was the hardest part. Spent about a day of debugging to get it working. So if your use-case doesn’t need complex sampling and C++ I would suggest just going with Gonum you would save yourself lot of time.
One of the things I didn’t realize coming from cython was that I had to compile C++ files manually and load that in cgo include flags.
header file
#ifndef BETA_DIST_H
#define BETA_DIST_H
#ifdef __cplusplus
extern "C"
{
#endif
double beta_sample(double, double, long);
#ifdef __cplusplus
}
#endif
#endif
Notice extern C, it’s needed for C++ code to be usable in go, not needed for C due to mangling. Another gotcha was that I couldn’t do any #include statements in header file, cgo linking fails in that case(for unknown reason). So I moved those to .cpp file.
To compile it
g++ -fPIC -I/usr/local/include -L/usr/local/lib betadist.cpp -shared -o libbetadist.so
Once compiled you can use it cgo.
cgo wrapper file
/*
#cgo CPPFLAGS: -I${SRCDIR}/cbetadist
#cgo CPPFLAGS: -I/usr/local/include
#cgo LDFLAGS: -Wl,-rpath,${SRCDIR}/cbetadist
#cgo LDFLAGS: -L${SRCDIR}/cbetadist
#cgo LDFLAGS: -L/usr/local/lib
#cgo LDFLAGS: -lstdc++
#cgo LDFLAGS: -lbetadist
#include <betadist.hpp>
*/
import "C"
func Betasample(alpha, beta float64, random int) float64 {
return float64(C.beta_sample(C.double(alpha), C.double(beta), C.long(random)))
}
Notice -lbetadist in LDFLAGS that is to link libbetadist.so. You also have to run export DYLD_LIBRARY_PATH=/fullpath_to/folder_containing_so_file/. Then I could run go run . it worked usually like a go project.
Integrating them all together with simple model struct with predict method is simple and takes less time comparatively.
Results
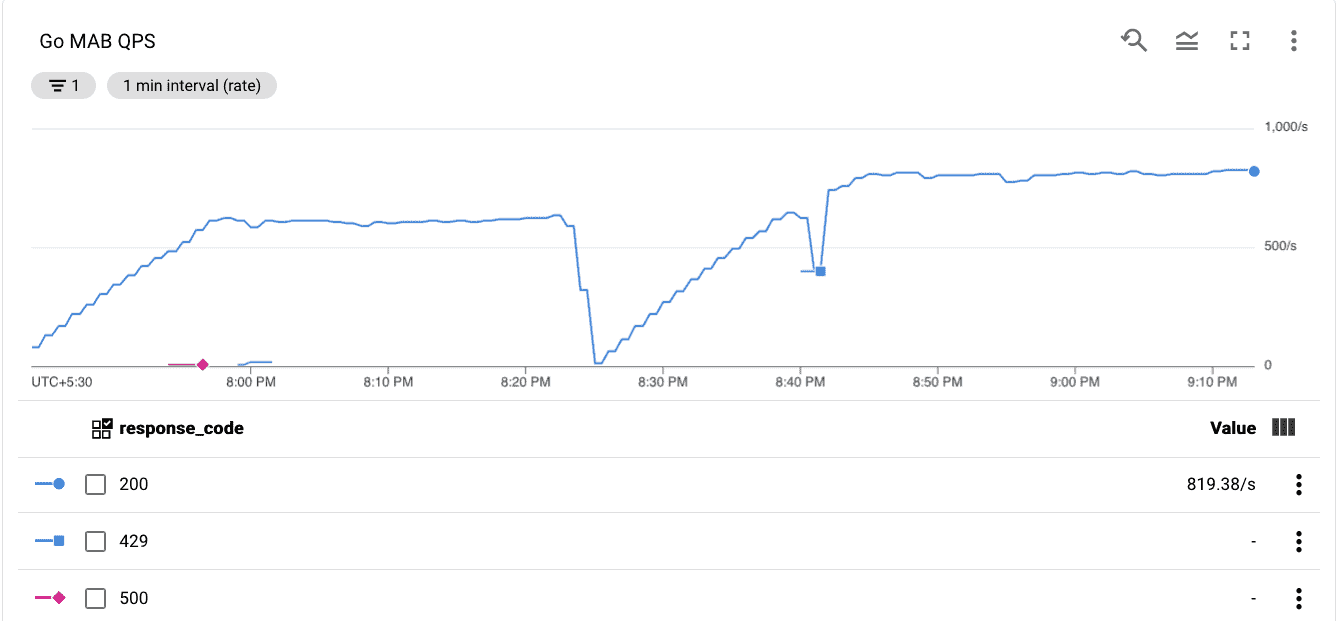
| Metric | Python | Go |
|---|---|---|
| Max RPS | 192 | 819 |
| Max latency | 78ms | 110ms |
| Max CPU util. | ~20% | ~55% |
That’s 4.3x improvement on RPS, that reduces our number of minimum node to 19 from 80, that’s a HUGE cost advantage. Max latency was slightly higher but that acceptable given python service saturates at 192 and degrades significantly if traffic raises beyond that.
Should I convert all my models to Golang?
Short answer: No.
Long answer: Go has great advantage in serving, but Python is still king for experimentation. I would only suggest go if the model is simple and its a long running base model not experiment. Go is not mature for complex ML use-cases yet.
So the elephant in the room, Why not Rust?
Well, Shiv did. Take a look. It is even faster than Go.